- Beranda
- Komunitas
- Hobby
- Do It Yourself
A Quick Overview of Spark For Data Science

TS
swethakrishn017
A Quick Overview of Spark For Data Science
Introduction
Apache Spark is an open-source cluster computing framework that is igniting the big data world. When compared to Hadoop, Spark's performance is up to 100 times faster in memory and 10 times faster on disc, according to Spark Certified Experts. In this blog, I will provide an overview of Spark architecture and the fundamentals underpinning it.
An open-source framework for cluster computing for real-time data processing is Apache Spark. Apache Spark's in-memory cluster computing, which accelerates application processing, is its key feature. Spark offers a programming interface with implicit data parallelism and fault tolerance for entire clusters. It is made to handle a variety of workloads, including streaming, interactive queries, iterative algorithms, batch applications, and more.
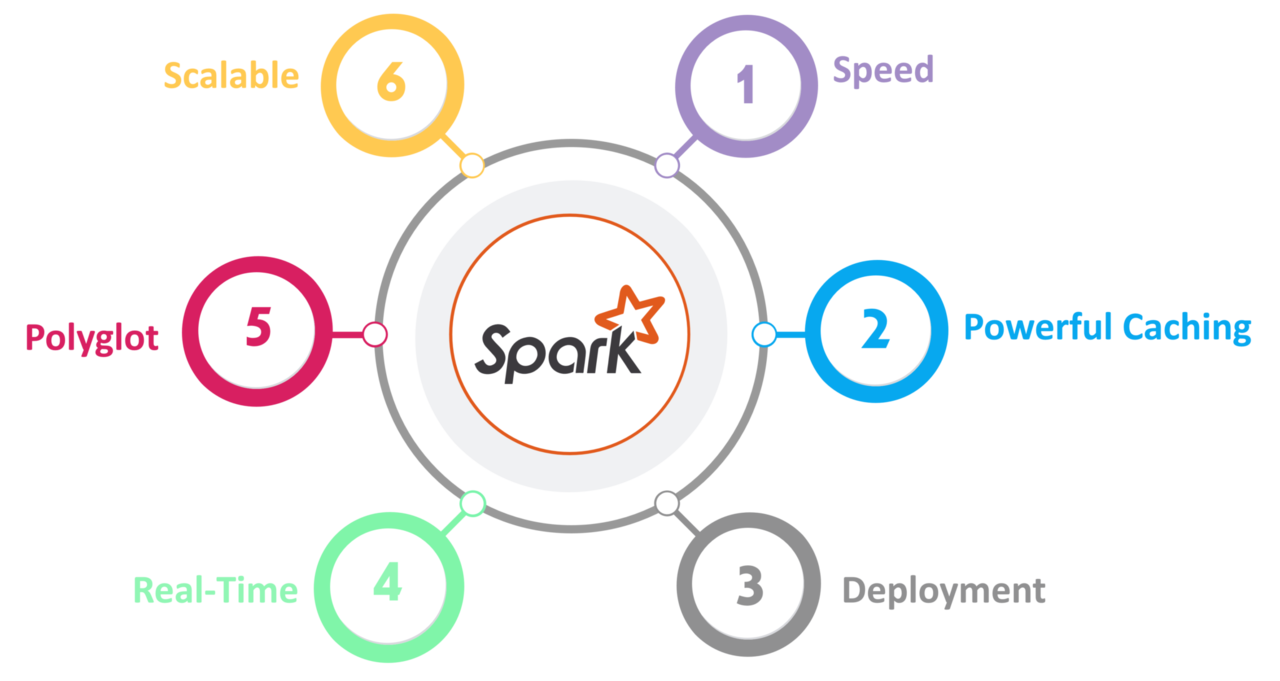
Features of Apache Spark:
Speed
Spark is up to 100 times faster for processing large amounts of data than Hadoop MapReduce. It can also reach this speed through carefully managed partitioning.
Strong Caching
A simple programming layer provides powerful caching and disc persistence capabilities.
Deployment
It can be set up using Mesos, YARN for Hadoop, or Spark's built-in cluster manager.
Real-Time
Due to in-memory computation, it provides low latency and real-time computation.
Polyglot
Spark offers high-level APIs for Java, Scala, Python, and R. These four languages are all capable of producing Spark code. Additionally, it offers Python and Scala shells.
Spark Ecosystem
The core API component, Spark SQL, Spark Streaming, MLlib, GraphX, and others comprise the Spark ecosystem. Check out the trending data science courseto learn the practical implementation of these tools.
Spark Core
Spark Core is the primary computing platform for massively parallel and distributed data processing. Additionally, additional libraries built on top of the core enable various streaming, SQL, and machine learning workloads. It oversees memory management, fault recovery, the scheduling, distribution, and supervision of jobs across a cluster, as well as communication with storage systems.
Spark Streaming
Real-time streaming data processing is done using Spark Streaming, a Spark component. This makes it a valuable addition to the Spark API. It makes it possible to process live data streams in a high-throughput, fault-tolerant manner.
Spark SQL
The new Spark SQL Module combines relational processing with the functional programming API of Spark. It supports both SQL and the Hive Query Language for data queries. If you are already familiar with relational database management systems (RDBMS), Spark SQL will Make it simple for you to move from your current tools and expand the capabilities of relational data processing.
GraphX
The Spark API for graphs and graph-parallel computation is called GraphX. As a result, it adds a Resilient Distributed Property Graph to the Spark RDD. On a broad scale, GraphX adds the Resilient Distributed Property Graph to the Spark RDD abstraction (a directed multigraph with properties attached to each vertex and edge).
MLlib (Machine Learning)
The machine learning library is referred to as MLlib. In Apache Spark, machine learning is carried out using MLlib.
SparkR
It is an R package that offers an implementation of a distributed data frame. However, it only supports operations like selection, filtering, and aggregation on very large data sets.
As you can see, Spark is stocked with high-level libraries that support R, SQL, Python, Scala, Java, and other programming languages. These common libraries improve the level of seamless integration in a complicated workflow. To expand its functionality, it also permits a variety of service sets to integrate with it, such as MLlib, GraphX, SQL + Data Frames, and streaming services.
Summary
We have now concluded the blog post on Apache Spark architecture. I hope you found this blog to be instructive and useful.
Check out the online and interactive data science course in Puneif you want to learn Spark and advance your career in the field by processing big data with RDD, Spark Streaming, SparkSQL, MLlib, GraphX, and Scala using Real Life use-cases. This training course includes project sessions, placement support, discussion forum and job referrals you as you learn.
0
116
0

Komentar yang asik ya
Komentar yang asik ya
Komunitas Pilihan