Halo agan dan aganwati baik yang masih newbie, pertengahan, maupun mastah.
Maaf sebelumnya kalau sedikit acak acakan maklum thread pertama
Disini ane mau sharing sedikit tentang kerjaan yang ane tekuni selama kurang lebih 1.5 tahun, okay kita langsung aja ke topik nya.
Quote:
apa itu Web Crawler?
Web Crawler merupakan sebuah Bot Internet yang digunakan untuk menelusuri World Wide Webdan melakukan indexing kepada tiap tiap website agar nantinya bisa kita pakai sebagai sumber referensi tanpa harus menelusuri lagi Website tersebut. Adapun nama lain dari web crawler adalah Web Spider
Beberapa mesin pencarian terkemuka seperti Google, Yahoo, & Bing sudah lama memakai metoda ini untuk meng-index semua website yang ada diseluruh dunia. Dan mungkin yang paling populer adalah Web Crawler dari Google yaitu Googlebot (sedikit referensi dari wikipedia http://en.wikipedia.org/wiki/Googlebot)
Quote:
bagaimana cara kerja Web Crawler?
Video resmi dari om Google
Spoiler for How Google Works:
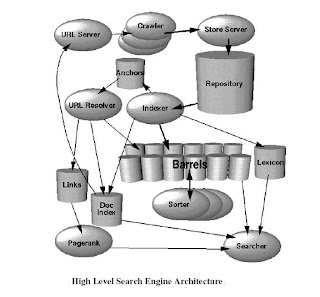
Flowmap Web Crawler secara umum
Spoiler for Flowmap Umum:
Dari gambar dan video diatas bisa kita simpulkan bahwa pada waktu yang telah di tentukan Web Crawlerakan meng-index satu per satu website yang telah ditentukan.
Proses peng-index-an ini bisa memakan waktu yang lama jika tujuan yang telah ditentukan amat sangat banyak, untuk kasus Google ini akan terasa menjadi terlihat lebih mudah dikarenakan Hardware Environment yang Google miliki sudah mendekati "God Like", tetapi jangan harap kita bisa mendekati kecepatan peng-index-an Google dengan Hardware Environment yang kita miliki (PC/LAPTOP)
Quote:
apakah kita bisa mengimplementasikan Web Crawler? dan apa tujuan dari Web Crawleryang kita buat nantinya?
Tentu saja kita bisa mengimplementasikannya walaupun hanya sepersekian persen dari apa yang telah Google lakukan, dan tujuan dari Web Crawler tergantung kepada keperluan masing masing individu/perusahaan, sebagai contoh untuk data miner yang dimana kita mengumpulkan data data dari beberapa website yang kita inginkan, yang nantinya data data tersebut bisa kita proses lagi menjadi informasi yang mungkin lebih penting seperti rating seseorang di website yang telah kita index atau pun untuk bahan Sentiment Analysis
Saat ini Web crawler sudah menjadi trending di dunia IT, beberapa Website membuat aplikasi yang menyuguhkan data data dari Web Crawler dan memprosesnya kembali menjadi informasi informasi penting bagi penggunanya. Contoh website yang menyuguhkan data hasil dari Web Crawler adalah TrendPo, OhMyGov, Whit.li, SproutSocial dan masih banyak lagi.
Quote:
bagaimana mengimplementasikan Web Crawleritu sendiri?
Ada beberapa cara yang bisa kita tempuh untuk mengimplemtasikan Web Crawler pada aplikasi kita, karena harus disesuaikan dengan kebutuhan individu/perusahaan yang membuat aplikasi tersebut nantinya.
Pertama yang harus kita persiapkan adalah Web Site yang akan kita "Scrape" / Kumpulkan datanya, saya akan ambil 3 contoh website
Facebook
Detik
Kaskus (Archive Kaskus)
Dari ketiga website diatas kita tentu menggunakan metoda pengambilan data yang berbeda beda. sebagai contoh untuk Facebook baiknya kita mengakses data dari API mereka yang disebut Graph API, untuk Detik kita bisa pakain [URL="http://rss.detik..com/"]RSS[/URL], dan untuk Kaskus kita bisa langsung masuk ke bagian Archive secara langsung dikarenakan untuk hanya membaca kita tidak memerlukan login terlebih dahulu.
Kedua kita harus mempersiapkan plug-in/library yang mumpuni untuk meng-handle semua kebutuhan kita dalam meng-implementasi-kan Web Crawler
Beberapa referensi plug-in/library yang pernah saya coba di beberapa bahasa pemrograman yaitu sebagai berikut :
SimpleDomHtml bagi agan dan aganwati yang menggunakan PHP
Selanjutnya agan harus mulai membuat code code dasar untuk mengambil data dari website tujuan, seperti contoh :
Code:
<?php
include(simpledomhtml.php); //menambahkan library simpledomhtml
$url = 'http://archive.kaskus.co.id/forum/21'; //url tujuan
$html = file_get_html($url); // mengambil semua data dari url tujuan
//sekarang saya akan tampilkan semua link yang muncul di archive kaskus
if($html){
foreach($html->find("div#forum ul li:not(:first) div:first") as $data){
echo $data->find('a:first', 0)->plaintext."\n"; //mengeluarkan text dari link
echo $data->find("a:first", 0)->href."\n"; // mengeluarkan url dari link
echo "--------------";
}
}
?>
contoh output :
Code:
Sticky:Laporan, Kritik, Saran, dan Pertanyaan Seputar The Lounge - Part 11
http://archive.kaskus.co.id/thread/13143203/0/laporan-kritik-saran-dan-pertanyaan-seputar-the-lounge---part--11
---------------------------------------
Sticky:Lomba Mini Video Cinta Indonesia [Hari Sumpah Pemuda]
http://archive.kaskus.co.id/thread/16921290/0/lomba-mini-video-cinta-indonesia-hari-sumpah-pemuda
---------------------------------------
contoh di atas merupakan Web Crawlerdalam bentuk PHP yang mengguanak library SimpleDomHTML, seperti yang bisa agan dan aganwati lihat saya menggunakan selector yang sama dengan selector yang digunakan oleh JQuery jadi selama agan bisa menggunakan selector JQuery atau minimal selector CSS maka tidak akan ada kesulitan berarti yang akan ditemui.
Setelah data yang diinginkan telah berada ditangan selanjutnya terserah agan dan aganwati, entah itu hanya akan dibuang atau akan disimpan atau diproses kembali itu saya kembalikan kepada yang membuat.
Dan untuk dua contoh lainnya silahkan agan dan aganwati coba sendiri, untuk RSS saya sarankan untuk memakai plug-in/library tambahan seperti MagPieRSS bagi agan dan aganwati yang menggunakan PHP, untuk Ruby on Rails tidak perlu tambahan apa apa karena Nokogiri sudah cukup meng-cover semua kebutuhan dan begitu juga dengan Python (BeautifulSoup)
Untuk sementara sekian sharing ilmu dari saya buat agan dan aganwati semua, jika response yang didapatkan cukup baik saya akan update beberapa cara yang bisa mempercepat performa Web Crawler ini.
sepertinya tidak lengkap jika saya tidak menambahkan kata kata ini pada sebuah thread di kaskus
Quote:
TS SELALU MENGHARAPKAN
DAN TIDAK MENERIMA
JANGAN LUPA
Quote:
BUDAYAKAN
Spoiler for Comment:
nona212 memberi reputasi
1
13.9K
Kutip
39
Balasan
Guest
Tulis komentar menarik atau mention replykgpt untuk ngobrol seru
Urutan
Terbaru
Terlama
Guest
Tulis komentar menarik atau mention replykgpt untuk ngobrol seru




")


